
L2是什么意思:深入解析L2缓存与L2正则化的核心概念及应用

在计算机世界里,L2这个名词经常出现。它可能指代缓存中的L2缓存,也可能涉及机器学习中的L2正则化。无论在哪种语境下,L2都扮演着重要的角色。今天我们就先来聊聊L2缓存是什么意思,它在计算机架构中的作用,以及它的工作原理和优势。
L2缓存是什么意思

说到L2缓存,我总是喜欢把它比作一个“中间人”。我们知道,CPU需要频繁地从内存中读取数据。但内存的速度相对较慢,如果每次CPU都需要直接访问内存,整个系统就会变得很慢。于是,聪明的工程师们设计了缓存这种东西。而L2缓存就是其中的一层,位于CPU核心和主内存之间。它的主要任务是存储那些最近被使用过的数据或者即将被使用到的数据。这样,当CPU需要这些数据时,就可以快速地从L2缓存中获取,而不必每次都去访问速度较慢的内存。
举个例子来说,就像你在厨房做饭的时候,会把常用的调料放在手边,而不是每次都要跑到储藏室去找。L2缓存的作用类似,它让CPU的工作变得更高效。当然,L2缓存也有大小限制,不可能无限扩大,所以它只能存储一部分最常用的数据。
L2在计算机架构中的作用
接着,我们再来看看L2缓存在计算机架构中的具体作用。其实,L2缓存就像是连接CPU和内存之间的桥梁。没有它的话,CPU和内存之间的通信会变得非常低效。L2缓存的存在不仅提高了数据访问的速度,还减轻了主内存的压力。因为很多数据都可以在L2缓存中找到,所以主内存不需要频繁地处理来自CPU的请求。
此外,L2缓存还有助于减少能耗。想象一下,如果CPU每次都需要直接访问主内存,那么功耗会显著增加。而有了L2缓存之后,CPU可以更少地依赖主内存,从而降低整体的能源消耗。这对于笔记本电脑或者移动设备来说尤为重要,因为它能延长电池的续航时间。
L2缓存的工作原理及优势
最后,我们深入探讨一下L2缓存的工作原理及其带来的优势。简单来说,L2缓存采用了一种叫“预测性”的机制。它会根据CPU之前的行为模式,提前将可能用到的数据加载到缓存中。这样一来,当CPU真正需要这些数据时,它们已经在L2缓存中等待了,大大缩短了响应时间。
这种工作机制的优势显而易见。首先,它提升了系统的性能,因为数据访问速度更快了。其次,由于减少了对主内存的访问次数,整个系统的功耗也得到了优化。另外,L2缓存还能改善多任务处理能力。因为在多任务环境下,不同任务可能会交替使用相同的数据,而L2缓存正好可以很好地支持这种场景。
通过以上的介绍,相信你对L2缓存有了更全面的认识。无论是它的基本概念、在计算机架构中的作用,还是工作原理和优势,都体现了L2缓存在现代计算体系中的重要地位。
在上一章中,我们探讨了L2缓存的相关知识。现在让我们把目光转向另一个同样重要的领域——L2正则化。L2正则化是机器学习和深度学习中的一个关键概念,它帮助模型更好地泛化到未知数据。那么,L2 regularization是什么意思?它的数学表达又有哪些意义?它在实际应用中如何发挥作用?接下来,我将从多个角度为你解答这些问题。
L2 regularization是什么意思
当我第一次接触L2正则化时,我把它理解为一种“约束工具”。简单来说,L2正则化是一种用来防止模型过拟合的技术。我们知道,在训练机器学习模型时,如果模型过于复杂或者数据量不足,模型可能会过度适应训练数据中的噪声或细节,从而导致在新数据上的表现变差。而L2正则化通过给模型参数添加额外的限制条件,让模型更倾向于选择那些较小的权重值,从而降低过拟合的风险。
具体一点讲,L2正则化的核心思想是在损失函数中加入一个与模型参数相关的惩罚项。这个惩罚项会随着参数值的增大而增加,因此模型在优化过程中会尽量避免使用过大的参数值。换句话说,L2正则化就像一位严格的老师,时刻提醒着模型不要过于依赖某些特定的特征,而是要更加均衡地利用所有可用的信息。
L2正则化的数学表达及其意义

接下来,我们来看一下L2正则化的数学表达形式。假设我们的原始损失函数为 ( J(\theta) ),其中 ( \theta ) 是模型的参数。那么,在引入L2正则化后,新的损失函数可以表示为:
[ J{\text{new}}(\theta) = J(\theta) + \lambda \sum{i=1}^{n} \theta_i^2 ]
这里的 ( \lambda ) 是一个超参数,用于控制正则化的强度。( \sum_{i=1}^{n} \theta_i^2 ) 则是对所有参数平方和的计算。这种形式的意义在于,当某个参数的绝对值较大时,它的平方值也会相应增大,从而对整体损失函数产生更大的影响。模型为了最小化总损失,就会倾向于减小这些参数的值。
从几何角度来看,L2正则化相当于在高维空间中对参数施加了一个球形约束。这意味着模型的参数会被迫靠近原点,形成一个更加平滑的解空间。这种特性使得模型更容易推广到未见过的数据,因为较大的参数通常会导致模型对训练数据的局部特征过于敏感。
L2正则化在机器学习和深度学习中的应用
最后,我们来聊聊L2正则化在实际中的应用。无论是传统的机器学习算法还是现代的深度学习框架,L2正则化都扮演着不可或缺的角色。例如,在线性回归模型中,L2正则化被称为岭回归(Ridge Regression)。它通过限制权重大小,有效减少了因多重共线性带来的问题。
而在深度学习领域,L2正则化更是广泛应用于各种神经网络架构中。想象一下,当我们构建一个包含成千上万参数的深度神经网络时,如果没有适当的正则化手段,模型很容易陷入过拟合的状态。通过在损失函数中加入L2正则化项,我们可以显著提高模型的泛化能力。此外,L2正则化还与其他技术如Dropout、数据增强等相辅相成,共同构成了完整的正则化体系。
通过以上内容,我们可以看到L2正则化不仅在理论上有着清晰的定义和深刻的数学背景,而且在实践中也展现出了强大的实用价值。
在前一章中,我们深入了解了L2正则化的理论和数学基础。接下来,我们将目光投向更广阔的领域,看看L2技术如何与其他相关技术进行比较,并探索它在现代科技中的具体应用案例。这一章会从多个角度为你解析L2缓存和L2正则化在实际场景中的表现。
L2缓存与其他层级缓存的比较
说到L2缓存,我总是忍不住拿它和其他层级的缓存做对比。L1缓存通常是处理器内部最近的缓存层,速度最快但容量最小。而L3缓存则通常服务于多个核心,虽然容量更大,但访问速度相对较慢。相比之下,L2缓存正好处于中间位置,既提供了比L1更大的存储空间,又保持了相对较高的访问速度。
举个例子来说,当你运行一个需要频繁访问数据的应用程序时,L1缓存可能会因为容量限制无法完全容纳所有热点数据。这时候,L2缓存就起到了至关重要的作用——它可以快速提供那些未命中L1的数据,从而减少对主内存的直接访问次数。这种设计让整个系统的性能得到了显著提升。因此,在多核处理器架构中,L2缓存往往成为平衡性能与成本的关键组件。

当然,不同厂商的设计理念也会影响L2缓存的具体实现方式。例如,某些高性能处理器可能采用更大的L2缓存以优化特定类型的工作负载,而另一些则通过改进缓存替换策略来提高效率。这些差异最终都会反映到实际用户体验上。
L2正则化与其他正则化方法的对比
除了L2正则化,还有其他几种常见的正则化方法,比如L1正则化和Dropout等。每种方法都有其独特的特点和适用场景。L1正则化通过在损失函数中加入参数绝对值的惩罚项,倾向于生成稀疏解,即模型中很多参数会被迫变为零。这使得L1正则化非常适合用于特征选择任务,因为它可以自动筛选出最重要的特征。
相比之下,L2正则化并不追求稀疏性,而是通过平方项的约束让参数值更加平滑且接近零。这意味着L2正则化更适合处理那些特征之间存在较强相关性的数据集。此外,L2正则化还具有较好的数值稳定性,尤其在面对大规模数据时表现出色。
值得一提的是,有时候我们会将L1和L2正则化结合起来使用,形成所谓的Elastic Net正则化。这种方式既能保留L1正则化的稀疏特性,又能利用L2正则化的平滑优势,为复杂问题提供更加灵活的解决方案。
L2技术在现代科技领域中的具体案例分析
最后,让我们来看看L2技术在实际应用中的几个典型案例。在计算机硬件领域,L2缓存已经成为几乎所有现代处理器不可或缺的一部分。无论是台式机、笔记本电脑还是智能手机,都可以看到L2缓存的身影。它的存在极大地提升了计算密集型任务的执行效率,比如游戏渲染、视频编码以及科学计算等。
而在机器学习领域,L2正则化同样无处不在。例如,在图像分类任务中,深度卷积神经网络通常会结合L2正则化来防止过拟合。此外,在自然语言处理领域,L2正则化也被广泛应用于文本分类、情感分析等任务中,帮助模型更好地理解复杂的语义信息。
总结一下,L2技术不仅在理论上有着坚实的支撑,而且在实践中展现出了强大的适应性和实用性。无论是在硬件层面还是软件层面,L2都扮演着关键的角色,推动着现代科技不断向前发展。
相关文章
-

off啥意思?不是‘关’也不是‘离开’——真正理解英语off的核心逻辑:基准线脱离感
还在死记‘off=关/离开/停止’?这篇文章彻底颠覆你对off的认知:它从不描述动作,而是精准标记‘脱离基准状态’的临界瞬间——...
-

第三方介入的合法性边界与效力保障:婚姻调解与数据合规双场景深度解析
本文系统拆解‘第三方介入’在婚姻家事调解与企业数据治理两大高风险场景中的法律根基、行为红线与实效路径。厘清谁可介入、如何正当介入...
-

邮箱地址格式规范全解析:从RFC标准到前端校验、Unicode兼容与GDPR合规实践
深度拆解邮箱地址格式本质——本地部分、@符号、域名结构、RFC 5322/6530差异、+标签归因、Punycode转换、大小写...
-
尾盘是什么意思?A股尾盘30分钟深度解析:从定义、机制到主力行为识别与实战交易铁律
新手常问尾盘是什么意思?本文彻底讲清A股尾盘(14:30-15:00)的本质——它不是收盘前的‘尾巴’,而是资金结算、主力调仓、...
-

2P是什么意思?揭秘网络用语2P的多重含义及游戏背后的文化现象
2P是什么意思?除了指双人游戏模式,它在网络社交中还有哪些隐晦用法?本文全面解析2P的词源、在游戏中的应用、引申义及其对人际关系...
-

通透是什么意思?揭秘真正活得通透的人具备的5个心理特质
你是否也想活得清楚、不被情绪困扰?本文深入解析‘通透是什么意思’,从心理学角度揭示通透的本质:自我觉察、情绪整合、内心澄明。读懂...
-

打压是什么意思?揭秘职场中隐性控制的真相与应对策略
你是否总被否定、功劳被忽视、发言被打断?这可能是职场打压。本文深度解析打压的定义、表现形式与心理机制,教你识别隐性排挤、信息封锁...
-

tw是什么意思?一文读懂网络缩写“tw”的多重含义
你是否经常看到‘tw’却不知道它代表什么?从台湾地区代码到时间扭曲、推文、暮光之城,本文带你全面解析‘tw是什么意思’在不同场景...
最新文章

我想你了怎么办|科学识别思念本质+4步行动指南:从心口一热到清醒选择
2026-02-07
微波炉的作用有哪些?揭秘它不只是热剩饭,而是厨房节奏控制器与分子级加热专家
2026-02-07


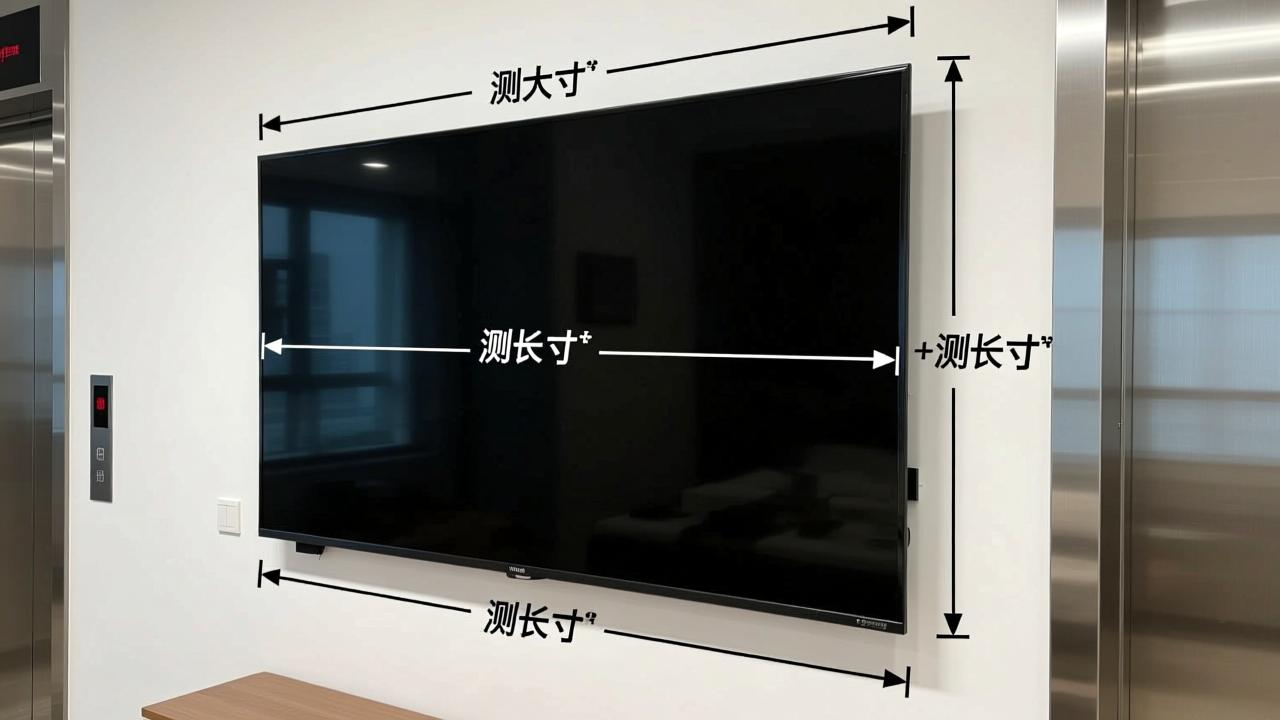
85寸电视多大?实测长宽高+挂墙尺寸+电梯搬运避坑指南(2024最新)
2026-02-07